Golang 常见的10种错误
前言:这里提到的错误,并不是那种“致命错误”,而是业务中的使用习惯的问题。如果不够了解语言的设计方式,导致使用习惯不当,可能就会引入一些设计不够好的代码。因此学习这些前人对使用方式的总结是很有帮助的。
话不多说,一起来看看都有哪些常见易犯的错误:
一、枚举默认值和json反序列化
先来看一段枚举的定义:
1 | type Status uint32 |
然后业务结构体 Request 引用了这个枚举
1 | type Request struct { |
最后就是常见的接口之后的反序列化过程了,如果是正常的接口返回,如下:
1 | { |
那么反序列化之后应该也是很正常的,调用方拿到了下游返回的状态信息,状态也都对得上。
但是如果下游有问题,没有返回这个状态:
1 | { |
这个时候后台拿到的状态是什么?又应该是什么?可以直接写段代码测试一下。
最终:一个更健壮的枚举定义:
1 | type Status uint32 |
别看是一个小问题,影响可不小,如果结构体设计阶段没有考虑到这个问题,需要发版之后再修复,可能要改的还有下游的结构体定义,而如果结构体是放在公共的pb 文件中,要改pb ,那么要影响到的服务可能就更多了。
所以元数据的定义永远是基础,牵一发而动全身。设计的时候还是要更考虑周全一些。需要从 业务逻辑转换成编程思维,考虑到更多的细节。
参考测试代码-enum_test.go
二、BenchMarking和内联
性能测试相关的代码,往往需要重复执行,如果写法不当,就很容易导致内联的问题:
1 | func clear(n uint64, i, j uint8) uint64 { |
这里先说明一下 testing.B 这个类的功能:它表示基准测试,在测试结束之后将会输出一段性能测试的结果
测试方法必须是 BenchMark 开头,另外执行测试需要带上 bench 参数:
1 | go test -bench=. benchmark_test.go |
测试结果:
goos: windows
goarch: amd64
pkg: github.com/smiecj/go_common_mistake
BenchmarkCleanBit
BenchmarkCleanBit-8 1000000000 0.339 ns/op
PASS
但是接下来要说到问题了:由于 clear 方法没有执行其他方法的调用,没有边际效应,所以会被内联,再加上其返回值也没有被外层接收,所以又会被进一步优化掉,直接不会执行。所以其实测试结果是不准的。
怎么确认 clear 方法被内联了呢?可以通过编译参数确认:
1 | go test -gcflags="-m" -bench=. benchmark_test.go |
-gcflags=”-m”: 打印编译过程中 golang 解析产生内联的详细过程
所以验证的方式也很简单,只要避免内联就可以了。结合这个性能测试的示例,大概有两种方式:
① 在 BenchMark 中设置一个局部变量去接收返回值
② clear 方法最上面设置取消内联
1 | //go:noinline |
新的测试结果:
goos: windows
goarch: amd64
pkg: github.com/smiecj/go_common_mistake
BenchmarkCleanBit
BenchmarkCleanBit-8 426727659 2.96 ns/op
PASS
③ 设置编译参数 -l 禁止内联
1 | go test -gcflags="-N -l -m" -bench=. benchmark_test.go |
-N:禁止编译优化
-l:禁止内联
测试结果:
goos: windows
goarch: amd64
BenchmarkCleanBit-8 376172835 3.13 ns/op
PASS
ok command-line-arguments 2.361s
扩展阅读:
High Performance Go Workshop
三、每次传参都应该用指针吗?
首先,就传递数据量来说,指针毫无疑问,在大多数时候还是更省空间的。(64位系统中是8个字节)
看起来似乎指针总比传值更好,对吧?其实不是的,我们可能只关注了参数本身的空间开销,却忽略了指针和值分别在栈和堆上的存储开销。
先从方法的返回值去理解返回参数和返回指针的区别,来看个例子:
1 | func getFooValue() foo { |
方法内部新建了result对象,这个对象只可能被方法内部访问,所以这个对象分配的空间就在栈上,不会在堆上。
然后,方法直接返回了值本身,这个动作会生成一份result的拷贝,存储在调用方的栈上,原result因为不会再被访问,将等待被GC回收。
再来看返回指针的情况:
1 | func main() { |
Go只有传值,所以对于指针p来说,它的空间申请和传递,都是和上一个例子一样的。但是对于foo对象本身,申请的时候必然不会在栈上申请,而会在堆上申请。这样才能让作用域扩大到调用方。
栈比堆更快的两个原因:
- 栈上对象不需要GC,从上面的例子可以看到,除非返回指针,否则栈内的一切对象都跟调用方没有任何关系,都是拷贝后返回,因此可以在方法结束后直接被标记。
- 栈上对象只会在当前routine被使用,不需要和其他协程同步,也就不会在堆上记录任何状态信息
总结来说,就是不管是传参还是返回,只要非共享的场景(当然,复合数据结构如map一般都是需要共享的),都建议传value,只有一定要传指针的时候才去传指针。
扩展阅读
Language Mechanics On Stacks And Pointers
四、break和条件控制语句
如下面这段代码,break 真的能够跳出循环吗?
1 | for { |
答案:break 其实是跳出 switch 的循环。但是golang 的switch 执行完成一个分支之后其他分支也不会执行的,所以 switch 的 break 其实没有什么意义
但是select 的break 就有意义了。所以下面这种情况也是要特别注意的,break 跳出的也不是循环
for {
select {
case <-ch:
// Do something
case <-ctx.Done():
break
}
}
常见的退出循环+switch的方式:break + 代码块名称
1 | OuterLoop: |
五、错误管理
error的处理一般满足两个原则:处理了就不要再向上继续抛出,必须给上层返回不一样的信息;没处理就一定要继续向上抛出
而go1.13之前提供的error 管理方法其实很少,所以这里我们使用 pkg/errors 这个工具来帮我们更好地管理自定义错误:
1 | import "github.com/pkg/errors" |
注意到判断错误类型使用对象的type判断就可以了,Cause和Wrapf需要配套使用
六、数组初始化
6.1 len 和 cap
我们知道数组有两个初始化参数,分别表示len和cap,分别表示长度和初始化长度。
比如初始化一个空数组:
var bars []Bar
bars := make([]Bar, 0, 0)
和Java不同的是,go把 cap 设置也半交给用户了(当不配置cap 的时候,len 就是 cap)。但是这也
比如当我们把 cap 设置成负数,或者小于 len 的时候,会发生什么呢?
直接测试一下: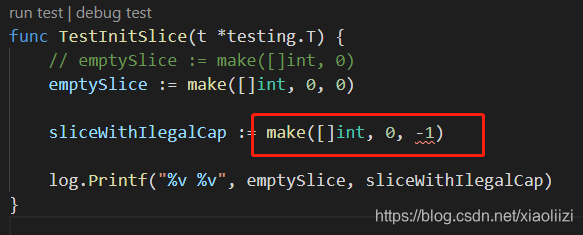
可以看到编译期 就已经直接报错了,不会让你能够执行这样的代码。我们可以从types/expr.go 中找到具体报错信息打印的地方。
6.2 设置len 还是 cap 的效率高
来看一种比较常见的场景:需要把数据库的对象转换成对外接口传递的对象。对象数量是确定的,需要怎么做呢?
有两种实现方式:
1 | func convert(foos []Foo) []Bar { |
1 | func convert(foos []Foo) []Bar { |
其实两种实现方式都可以,但是前者效率显然高一些,因为空间是已经分配好的,而后者虽然cap 设定了,但是随着 不断append 元素,底层也是要不断地进行数组的拷贝的。
译者:文章这里基本没有从源码说明效率高的原因,后续考虑新开一篇,从makeslice 方法去分析两种方式真正的差异
七、context 管理
7.1 什么是context
官方概念:
A Context carries a deadline, a cancelation signal, and other values across API boundaries.
这里说明了context可以带的三类信息:deadline(超时配置)、cancelation(终止动作)和values(键值对)
7.2 什么时候应该用context
前两个信息是context最常用的信息和功能,最常用的场景就是rpc调用,来看看一个grpc使用示例:
1 | ctx, cancel := context.WithTimeout(parent, 100 * time.Millisecond) |
WithTimeout 方法内部就是设置了 deadline,context 将会在超时时间到来的时候触发 Done 对应的channel close。这样我们可以通过 <- context.Done) 来做一些提前结束的操作,比如释放资源,避免超时请求一直阻塞其他正常请求。
总结一下,凡是涉及到上下游关系的都应该用context来处理调用关系,下游不应该忽略上游传下来的context。
扩展阅读:
Understanding the context package in golang
八、从来不用 -race 参数
根据 报告-Understanding real-world concurrency bugs in Go ,尽管go 的设计初衷是“更少错误的高并发”,但是现实中我们依然会遇到并发带来的问题
尽管 race 检测器不一定可以检测出每一种并发错误,但是它依然是有价值的,在测试程序的过程中我们应该始终打开它。
相对其余9个错误来说,竞态条件是能直接导致程序崩溃的,所以这一节应该是最重要的一部分,建议gopher 在平时开发中都尽量留意这一点,测试和调试工作要做好。
但是 开启race 也不代表 冲突能够马上检查出来,也是要有冲突的时候,才会有Warning信息。所以建议采用线上环境留一个节点用来开启竞态检查的方式。
扩展阅读:
Understanding real-world concurrency bugs in Go
Does the Go race detector catch all data race bugs?
自己写的示例-git-race_test.go
九、使用文件名作为输入(方法设计不满足SOLID原则)
9.1 从问题出发
来看一个常见的go 工具类开发需求:需要开发一个通用的读取文件行数的方法。项目中肯定会把这个方法封装到公共包的。
一种比较直接的思路,就是设置文件名作为传参,如下:
1 | func count(filename string) (int, error) { |
这种方式看上去功能没有任何问题,但是忽略了具体使用场景。如:
- 文件编码:当然你可以让方法增加一个传参,但是不符合接下来说到的开闭原则
- 单元测试:测试读取一个空文件场景。那么单测可能还需要先在本地创建一个空文件
这些细节,都会导致这个方法看上去完美,实际使用起来限制却很多。
9.2 SOLID 原则
SOLID 是面向对象编程中很重要的原则,由 总结而来。
- S 表示 Single Responsibility (单一原则):一个方法只做一件事
- O 表示 open-close principle (开闭原则):方法对扩展开放,对修改封闭
从这个例子就是很好的说明:S 和 O 它实际都不满足,方法做了读取文件和扫描文件行数两件事、方法可能还需要因为文件编码做格式 做适配修改
9.3 优化版本
借鉴 go 对 io.Reader 和 io.Writer 的实现思路,我们可以将传参改成这样:
1 | func count(reader *bufio.Reader) (int, error) { |
这样不仅满足和 S 和 O,方法的扩展性其实也加强了:可以读取文件流或者 http 流等的输入
调用端:
1 | file, err := os.Open(filename) |
单测:读取一行字符串流
1 | count, err := count(bufio.NewReader(strings.NewReader("input"))) |
因此,设计思想也非常重要,尽管代码规范之类的问题并不会直接导致程序运行问题,但是显然它的影响更为深远。
十、协程和循环中的局部变量
10.1 协程共用循环的局部变量
下面这段示例,会输出什么?
1 | func TestRoutineRace(t *testing.T) { |
显然目的是想打印 1、2、3的,但是结果却都是3
这是因为 子协程中,打印用的都是同一个局部变量i,这个i 在循环结束之后会变成3,所以最终打印的结果就都是3 了(大部分时候)
利用刚才学的race,这种使用协程的错误方式也可以通过 -race 参数 提前检测出来。
go test -v -race routine_test.go
检测结果:
……
WARNING: DATA RACE
Read at 0x00c000116140 by goroutine 8:
command-line-arguments.TestRoutine.func1()
D:/coding/golang/go_common_mistake/routine_test.go:16 +0x44
Previous write at 0x00c000116140 by goroutine 7:
command-line-arguments.TestRoutine()
D:/coding/golang/go_common_mistake/routine_test.go:14 +0x104
testing.tRunner()
G:/Program Files/Go/src/testing/testing.go:1127 +0x202
……
从错误信息可以看到,省略的部分还有其他协程,同样的警告信息。仔细分析下来就可以得到协程用的都是同一个局部变量的结论了。
怎么样,马上就体验到 -race 参数的作用了,是不是很妙
10.2 避免直接使用循环中的局部变量
对于这种情况有两种解决方法:
1)go func 加上入参
1 | for _, i := range ints { |
2)循环内使用单独的局部变量
注意虽然这里的I 依然是局部变量,但是对每个开启的协程来说已经不是同一个了,每次进入循环的I 都是不一样的。
但是这里我更推荐第一种写法,逻辑更加清楚