大数据任务调度和数据同步组件初探
背景
数据从最原始的状态,可能是一个 excel,一个文本,或者是来自业务数据库的数据,格式各种各样,落地到数据仓库、数据湖中,数据的同步过程 是必不可少的
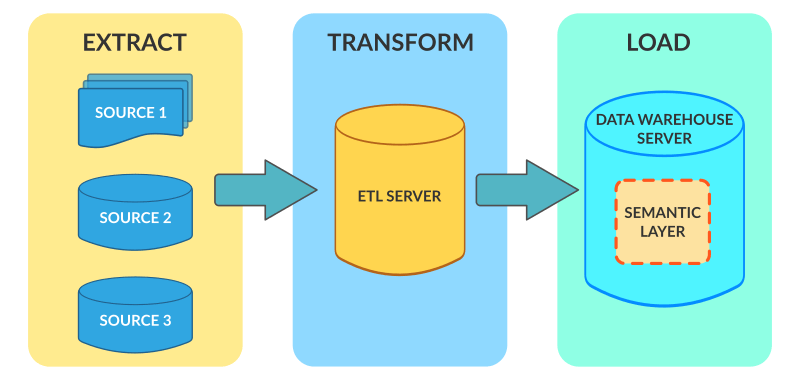
传统的数据同步方式主要是基于定时任务的模式,通过任务调度服务,每天定时将原始数据提取(extract),进行清洗处理,比如过滤掉重复数据(transform),最后存入数仓(load),即 ETL 任务模式。这种模式对数据的实时性要求不高,常见的同步工具有 datax、sqoop
实时同步,则需要让同步任务一直处于运行状态,有新数据进来需要在秒级别内更新。这种情况下传统的调度模式就不能满足了,需要能时刻监测数据同步状态、管理和启停任务、甚至动态分配任务资源。一种常见的模式是 任务通过 spark / flink 等流式任务引擎去执行,然后在上层通过 k8s 或其他任务管理平台 进行调度
本质上实时同步数据的模式和 ETL 是一样的,对数据依然有 抽取、清洗和写入的操作。只是时效性、任务管理复杂度、资源动态分配能力上,要求会更高
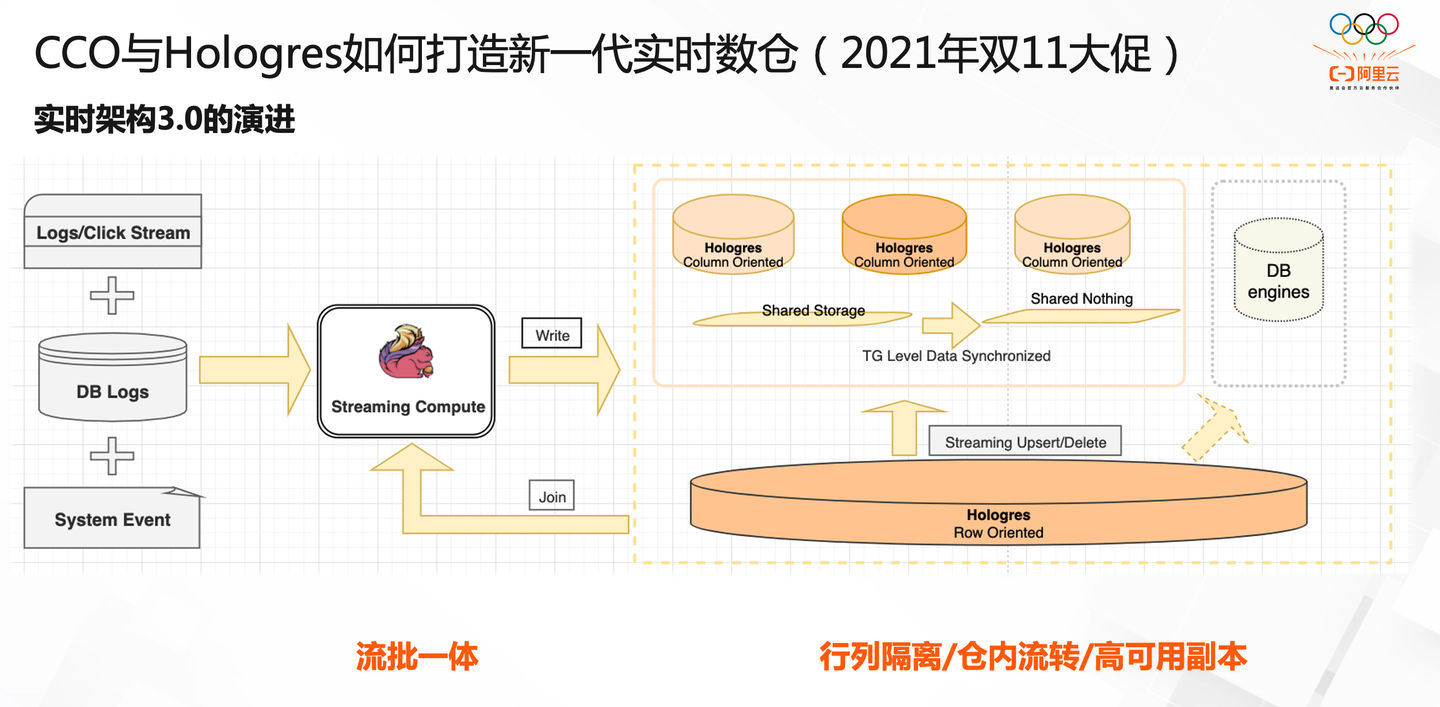
图片来源-DataFunTalk:阿里建设一站式实时数仓的经验分享
搭建可以在公司内通用的 EMR 平台,除了满足数据同步的功能,还需要提供任务调度的功能,因为用户的任务各种各样,可能是自定义的 spark / flink 任务,python 脚本 对数据自行处理的任务 等等,所以需要提供能让用户自行上传任务、执行任务的平台
不过相比数据同步 离线和实时同步架构相差较大,任务调度平台架构的发展则不离其宗,基本变化不大
本文将会对业界主流的任务调度服务 和 数据同步服务 做一些介绍,大家可以参考,择优选择更适合自己业务需求的服务 进行尝试
任务调度组件
这里列举三个主流的任务调度服务: azkaban、airflow 和 dolphinscheduler。我们先分别看基于这三个组件 数仓的架构可能是什么样的,然后系统对比,最后大致看下使用页面
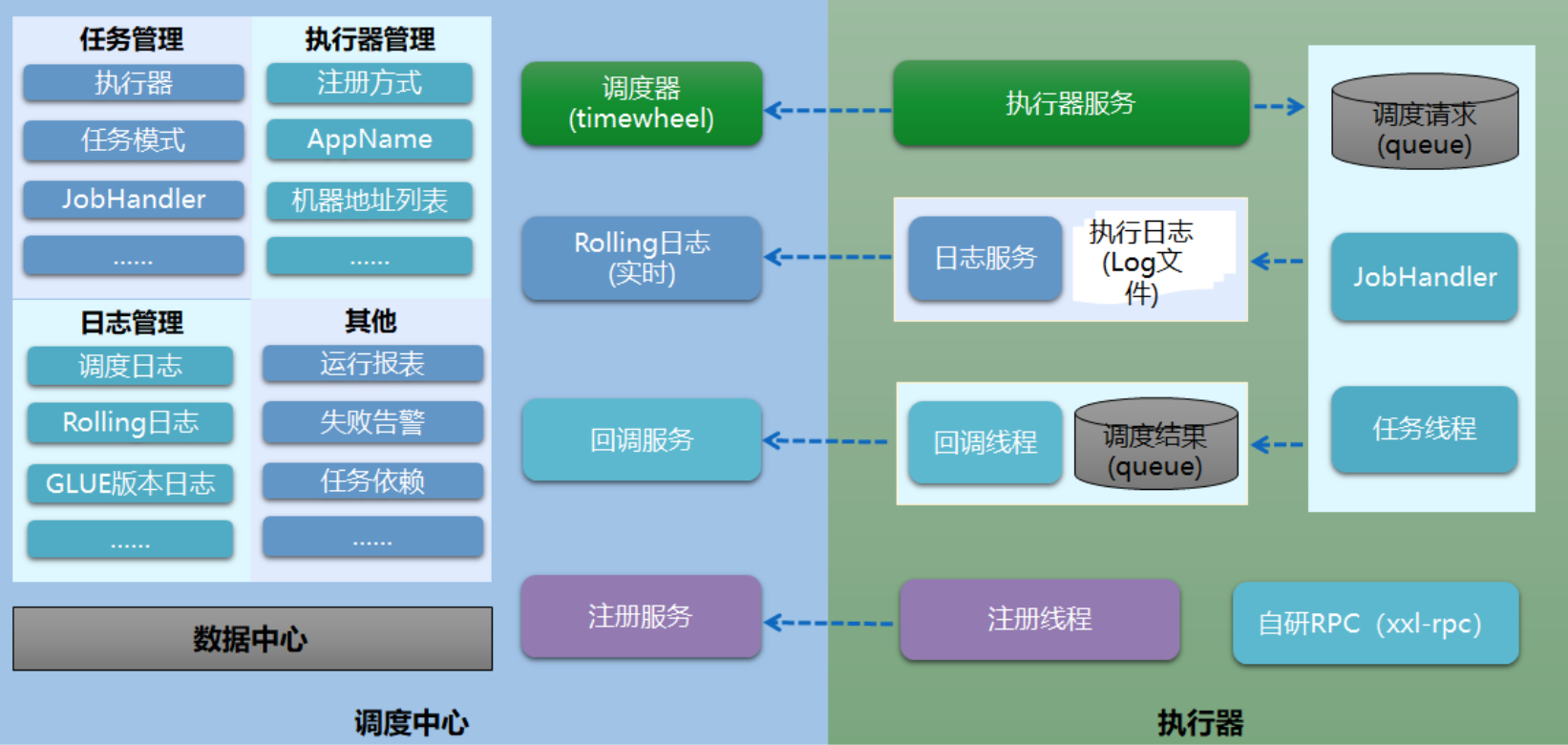
传统离线数仓: azkaban
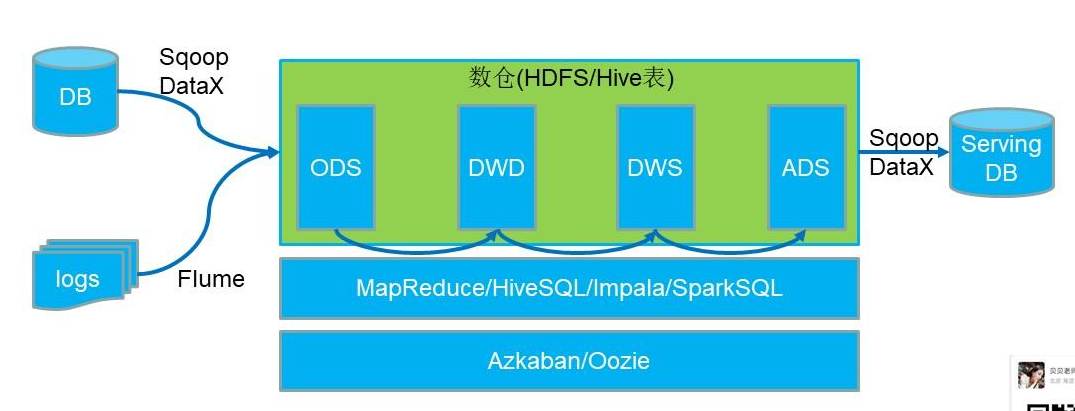
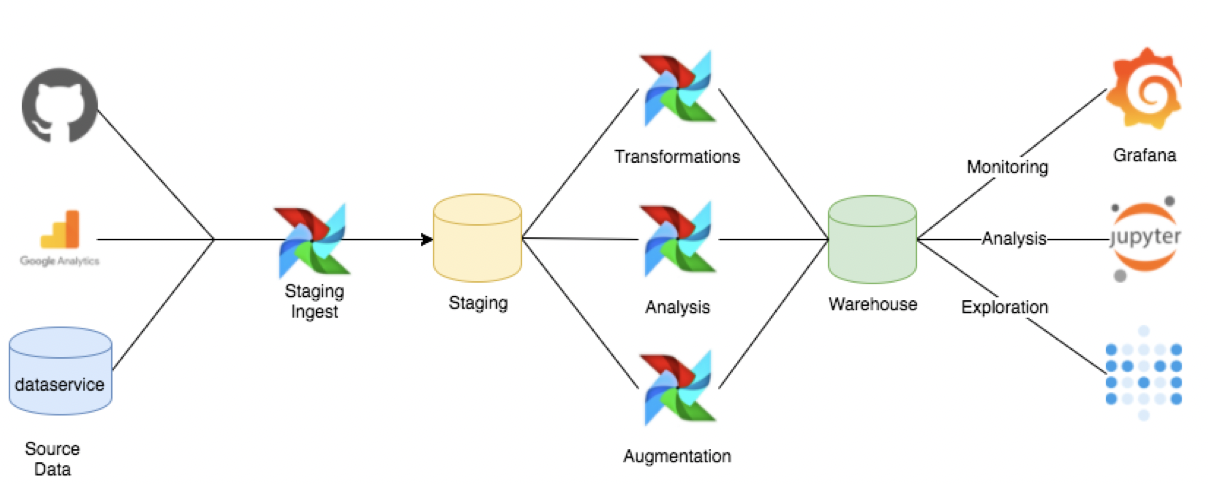
实时离线融合: airflow
实时离线融合: dolphinscheduler
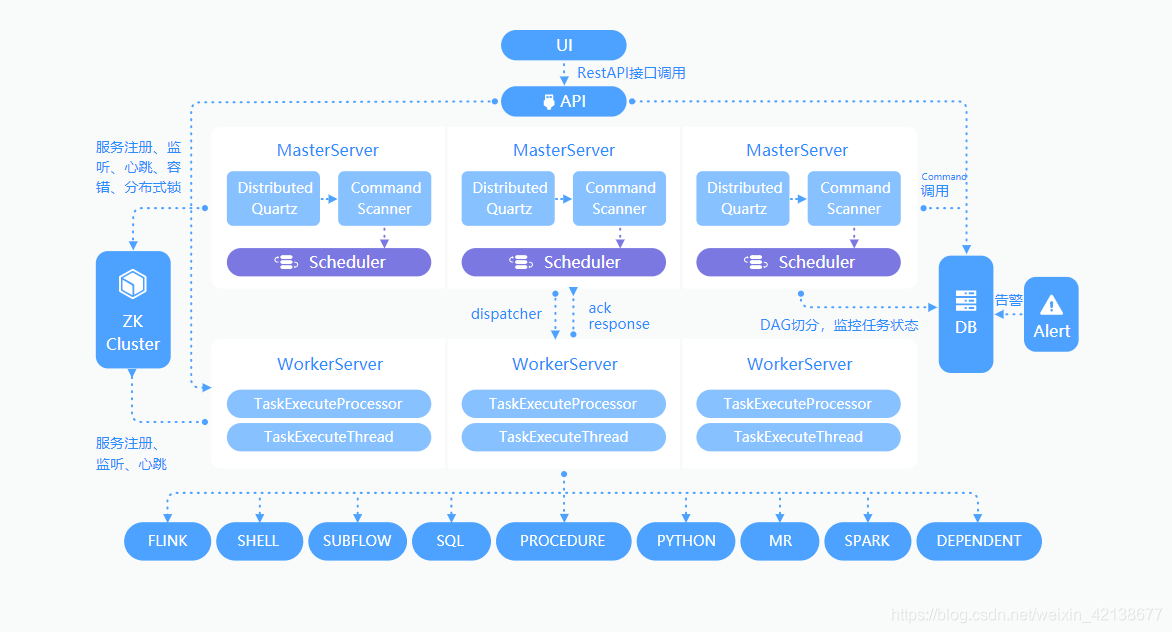
基于DolphinScheduler的使用浅谈数仓分层及模型设计
对比
大数据调度平台分类大对比(Oozie/Azkaban/AirFlow/XXL-Job/DolphinScheduler)
| 特性\组件 | airflow | dolphinscheduler | azkaban |
|---|---|---|---|
| web界面 | 有,功能比较多 | 有,且支持中文 | 有,比较简单 |
| 工作流语法 | python代码内定义,可通过界面查看但不能编辑 | 可视化编辑,对小白很友好,但不适合通过代码编排 | 配置文件 |
| 跨dag/project依赖 | 支持,可通过 ExternalTaskSensor 配置 | 不支持 | 不支持 |
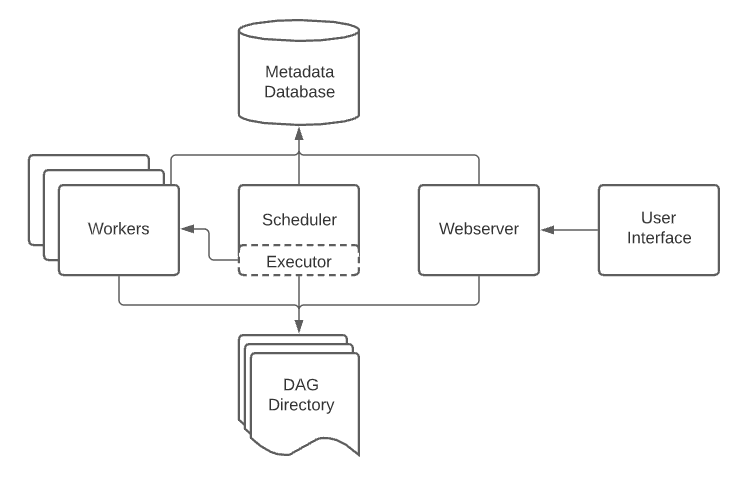
| 易用程度 | 安装和维护上手难度高,组件包括 WebServer、Scheduler、Worker | 安装维护上手难度高,组件包括 master、api、alert、worker 等,不过界面支持中文,可视化编辑任务比较友好 | 上手难度低,只有 webserver、executor 两个组件 |
| 变量定义 | 支持全局参数,和一些内置模板变量,如 | 不支持全局变量 | 不支持全局变量 |
| 调度中心HA | 支持 ,对 db 版本有要求(mysql >= 8) | 支持 | 不支持 |
| 执行器HA | 支持 | 支持 | 支持 |
| 权限管控 | 支持用户、任务级别配置 | 用户角色支持管理员、普通用户两种,不支持项目层级配置 | 支持用户、任务级别配置 |
| 任务监控 | 可通过定义 on_failure_callback 在任务结束后触发提醒,示例,支持metrics | 支持任务告警,支持通过企业微信、飞书等方式发送 | 可配置 job 的 failure.emails 让任务失败后发送邮件提醒 |
总结: ds 对各种 ETL 任务类型的界面化配置支持更好,airflow 更适合 python 基础较好的团队使用,编排任务代码化 笔者认为也是一种趋势。azkaban 较为传统,使用起来更简单,也更适合定义流程简单的 ETL 任务,但是相比前两个组件,更新不是特别活跃
airflow 架构和界面
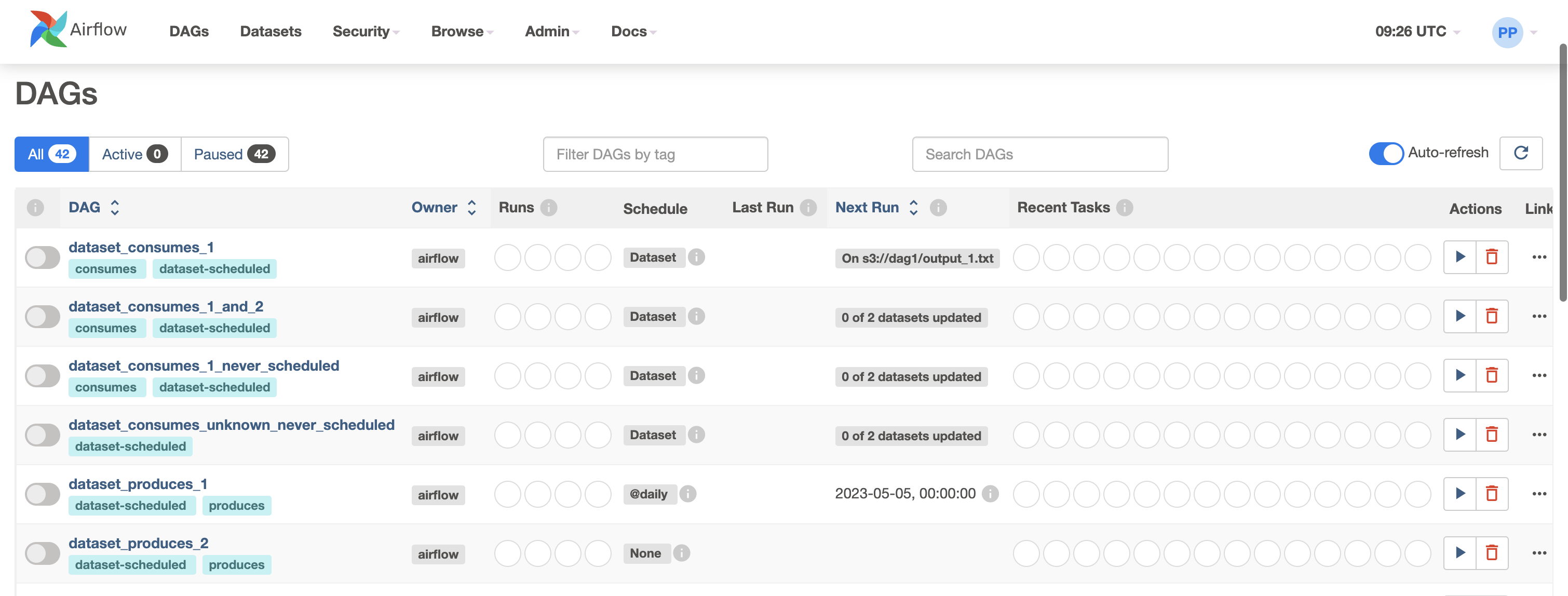
dolphinscheduler 界面
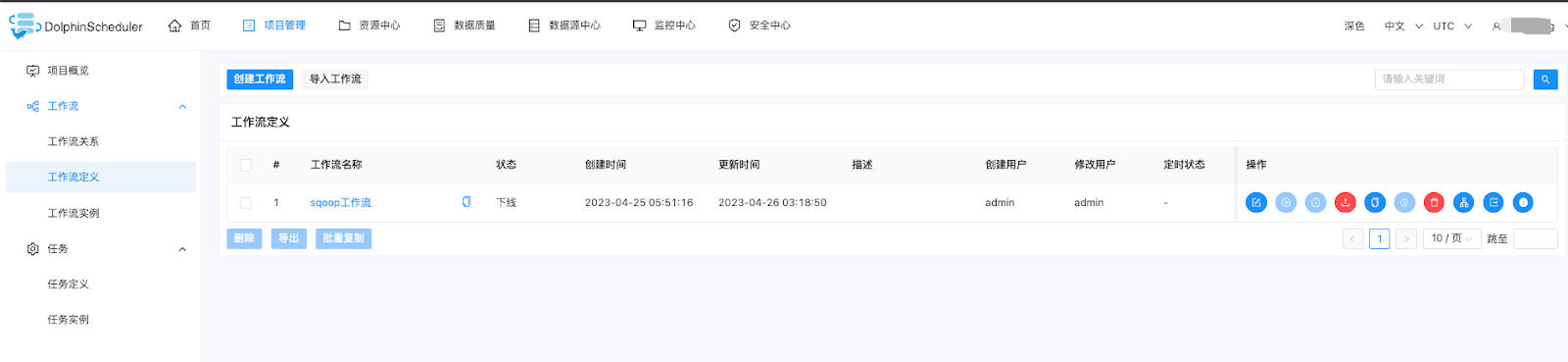
azkaban 架构和界面
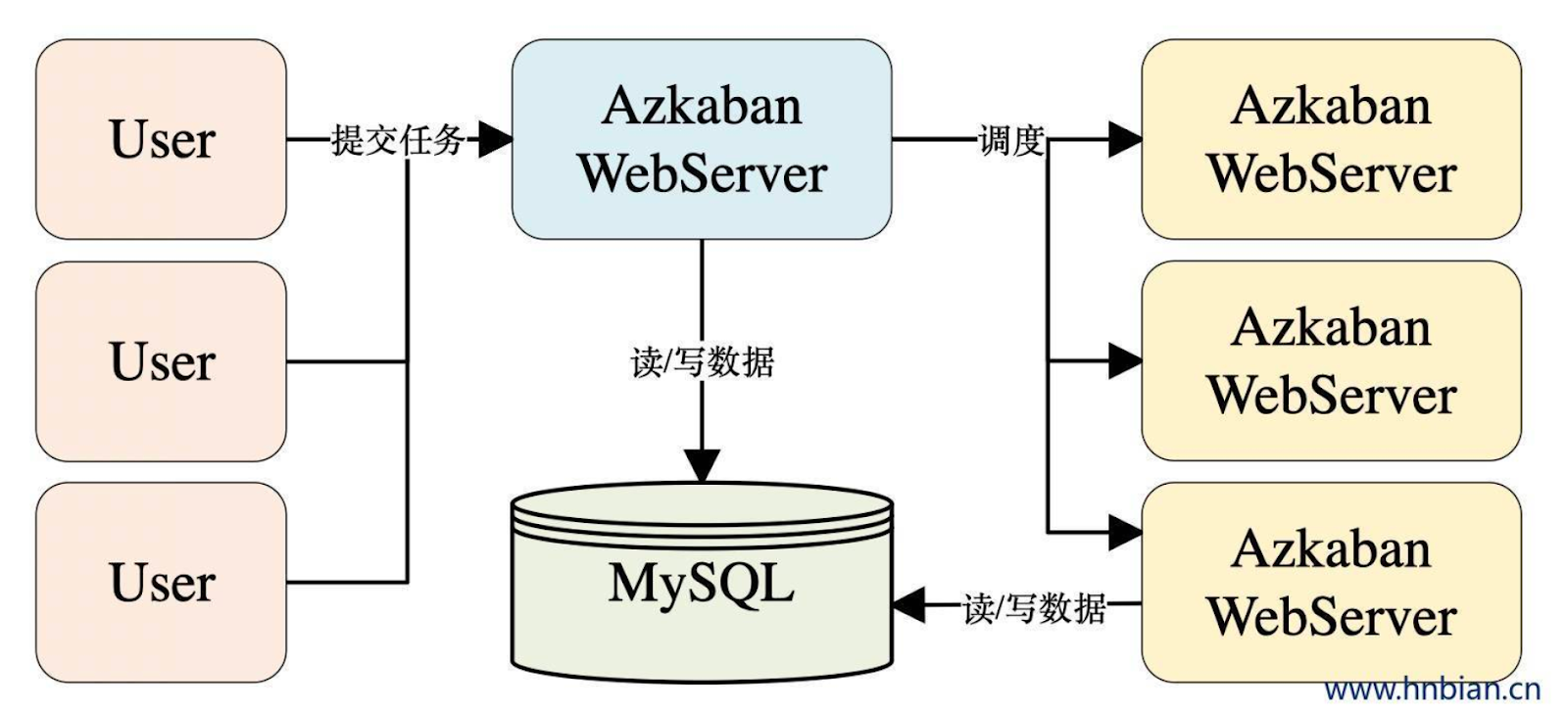
数据同步组件
对数据同步而言,支持更多的数据源是更重要的,传统数据同步工具,如 sqoop、datax ,都是对基于hadoop的传统数仓、基于关系型数据库 支持更好,不过对更现代的 OLAP、甚至湖仓一体的架构支持并不够好
随着发展,功能更强大的同步组件 如 seatunnel、chunjun 也逐渐占有了一席之地,在业务使用实际场景中可以优先选择它们
sqoop
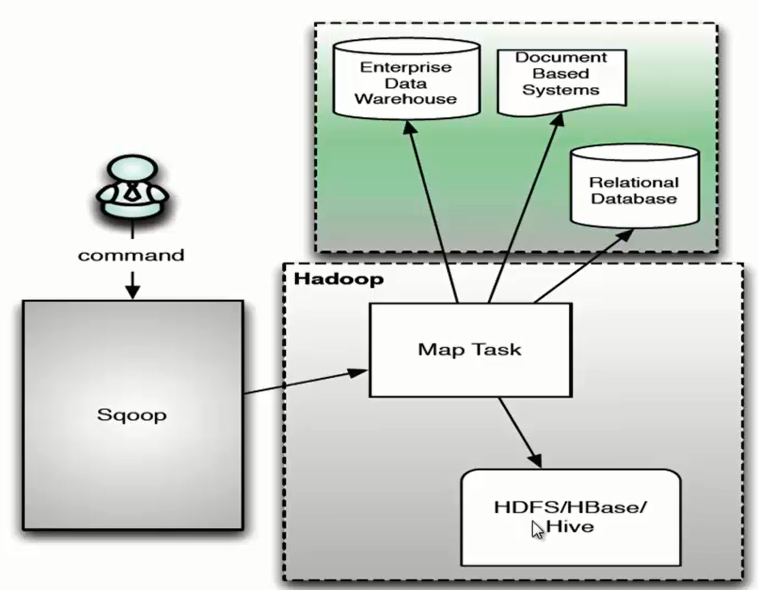
【知识】ETL大数据集成工具Sqoop、dataX、Kettle、Canal、StreamSets大比拼
特点:
- 离线全量同步,不支持增量导入
- 仅支持关系型数据库,比如从 mysql 同步到 hive
- 任务运行方式: mapreduce
datax

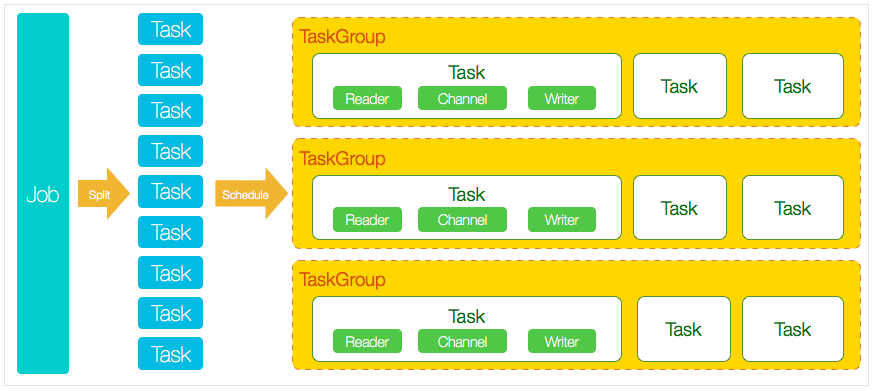
特点:
- 相比 sqoop 支持的数据源更丰富,支持非关系型数据库(如从 mysql 写到 hdfs、mongodb、es 等)
- 表字段的映射,必须提前写成json配置
- 同步任务在单节点运行(在执行 datax 的节点运行)
canal
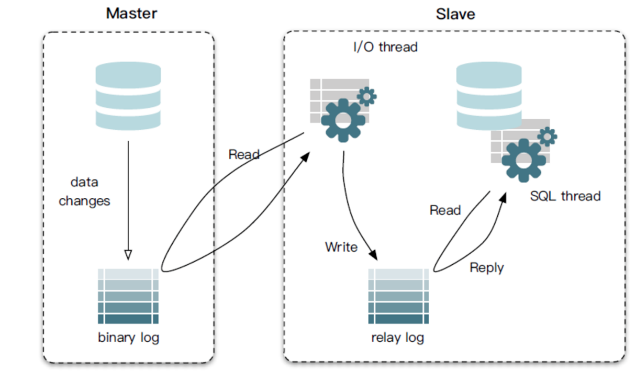
特点:
- 只能同步增量数据(本质:模拟 mysql slave 进行数据同步)
- 支持数据源: kafka、rocketmq、hbase、elasticsearch
- 实时任务管理:需要单独部署管理服务,如 cloudin-datax、Canal Admin
datalink
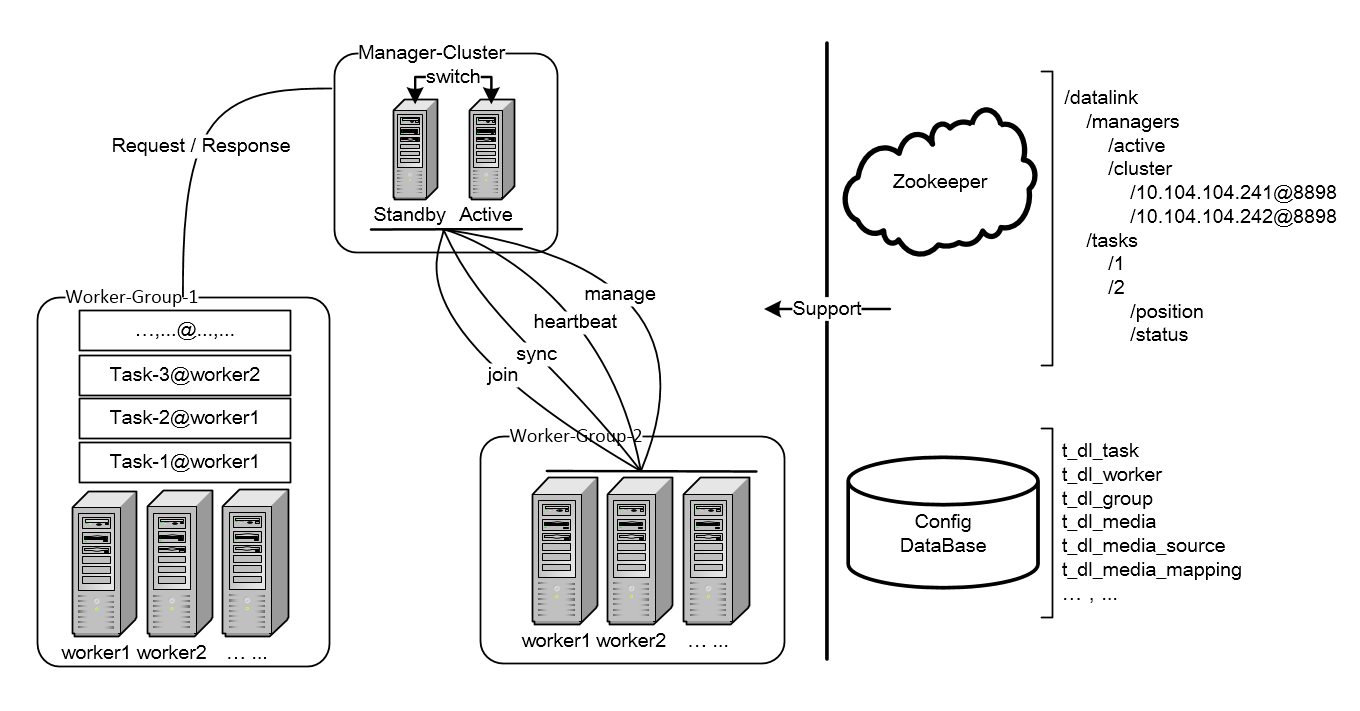
特点:
- 支持增量数据同步任务的管理,基本任务启停、同步状态检查等
- 对 canal 、datax 等同步工具进行了封装,支持数据源: mysql、hbase、elasticsearch、kafka、kudu
- 神州租车开源,现在不再维护,不过基本功能比较完善
seatunnel
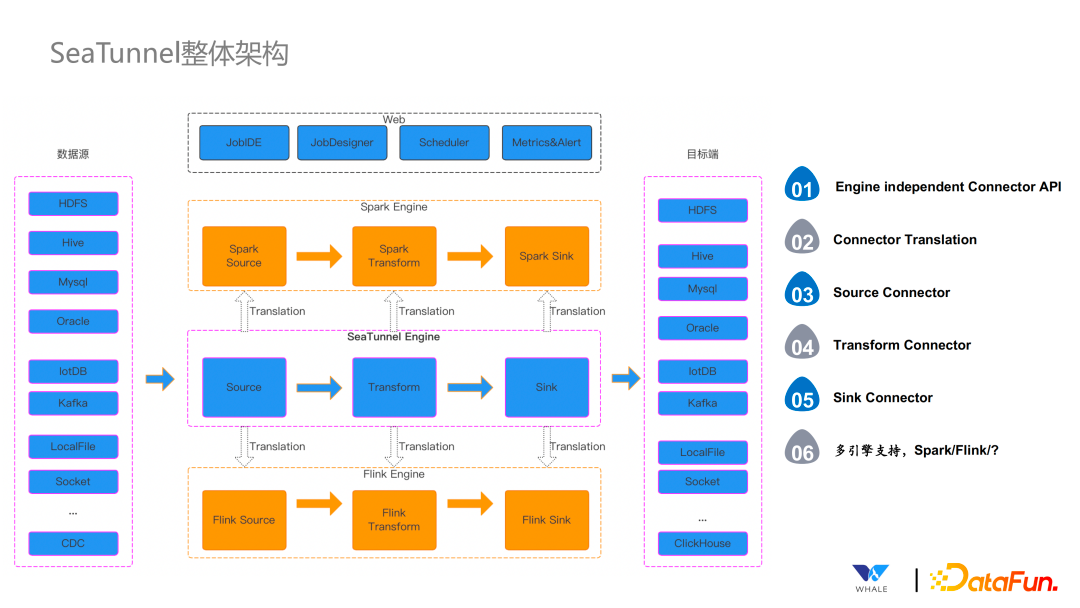
【大数据】什么是数据集成?(SeaTunnel 集成工具介绍)
特点:
- 通过spark / flink 方式同步数据,支持更多现代数据源(clickhouse、doris、iceberg 等)
- UI 还不是很完善
- 笔者后续会更详细地体验这个工具,补充和更多实时同步组件的使用对比
airbyte
特点:
- 完全云原生化的数据同步服务,一个同步任务对应一个容器
- 适用ETL 场景(配置定时任务,最小周期5分钟,并不是完全实时)
- 上手难度高,学有余力可以尝试
展望
对于任务调度平台来说,本质上都是 定时 + 触发任务 + 管理任务 的使用机制,基本架构都离不开 scheduler + task worker,相差不大
但对于数据同步组件来说,现在有一种离线往实时迁移的趋势。所以 诸如 sqoop、datax 这种传统离线数据同步方式应该会逐渐淡出,相比较,seatunnel 、 airbyte 这种后起之秀 一定会越来越强大。不过,实时也意味着需要更灵活的资源分配方式,需要掌握更深的技术栈,对开发人员要求也会更高
Anyway,所有大数据架构的底层都是存储。数据如果是存放在 hdfs + hive 这种传统数仓架构,对实时性要求不高,那么 sqoop + azkaban / airflow 模式就完全足够了。数据需要存放在 clickhouse / kudu 这种 OLAP 存储,业务需要获取实时数据进行分析,那么就需要 seatunnel 这种实时同步的服务。没有绝对的哪个更好,只有更合适